垃圾收集器(CMS-G1-ZGC)与垃圾回收算法
垃圾收集器(CMS-G1-ZGC)
CMS 垃圾收集器
JDK1.5时引入,JDK9被标记弃用,JDK14被移除
CMS(Concurrent Mark Sweep,并发标记清除)收集器是以获取最短回收停顿时间为目标的收集器(追求低停顿),它在垃圾收集时使得用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
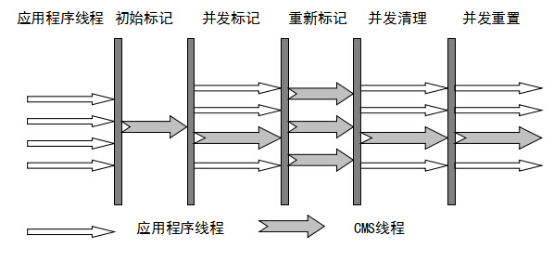
- 初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记。
- 并发标记:使用多条标记线程,与用户线程并发执行。此过程进行可达性分析,标记出所有废弃对象。速度很慢。
- 重新标记:Stop The World,使用多条标记线程并发执行,将刚才并发标记过程中新出现的废弃对象标记出来。
- 并发清除:只使用一条 GC 线程,与用户线程并发执行,清除刚才标记的对象。这个过程非常耗时。
并发标记与并发清除过程耗时最长,且可以与用户线程一起工作,因此,总体上说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。
CMS 的缺点:
- 吞吐量低
- 无法处理浮动垃圾
- 使用“标记-清除”算法产生碎片空间,导致频繁 Full GC
对于产生碎片空间的问题,可以通过开启 -XX:+UseCMSCompactAtFullCollection,在每次 Full GC 完成后都会进行一次内存压缩整理,将零散在各处的对象整理到一块。设置参数 -XX:CMSFullGCsBeforeCompaction 告诉 CMS,经过了 N 次 Full GC 之后再进行一次内存整理。
G1 通用垃圾收集器
JDK7引入,JDK9取代CMS成为默认垃圾收集器,至少要4G内存才推荐使用G1
G1 是一款面向服务端应用的垃圾收集器,它没有新生代和老年代的概念,而是将堆划分为一块块独立的 Region。当要进行垃圾收集时,首先估计每个 Region 中垃圾的数量,每次都从垃圾回收价值最大的 Region 开始回收,因此可以获得最大的回收效率。
从整体上看, G1 是基于“标记-整理”算法实现的收集器,从局部(两个 Region 之间)上看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
这里抛个问题
一个对象和它内部所引用的对象可能不在同一个 Region 中,那么当垃圾回收时,是否需要扫描整个堆内存才能完整地进行一次可达性分析?
并不!每个 Region 都有一个记忆集(Remembered Set),用于记录本区域中所有对象引用的对象所在的区域,进行可达性分析时,只要在 GC Roots 中再加上记忆集即可防止对整个堆内存进行遍历。
如果不计算维护 Remembered Set 的操作,G1 收集器的工作过程分为以下几个步骤:
- 初始标记:Stop The World,仅使用一条初始标记线程对所有与 GC Roots 直接关联的对象进行标记。
- 并发标记:使用一条标记线程与用户线程并发执行。此过程进行可达性分析,速度很慢。
- 最终标记:Stop The World,使用多条标记线程并发执行。
- 筛选回收:回收废弃对象,此时也要 Stop The World,并使用多条筛选回收线程并发执行。
ZGC 收集器(低延迟垃圾收集器)
JDK11推出
与Shenandoah和G1一样,ZGC也采用基于Region 的堆内存布局,但与它们不同的是,ZGC的Region具有动态性——动态创建和销毁,以及动态的区域容量大小。
-
小型Region:容量固定为 2MB,用于放置小于256KB的小对象
-
中型Region:容量固定为32MB,用于放置大于等于256KB但小于4MB的对象
-
大型Region:容量不固定,可以动态变化,但必须为2MB的整数倍,用于放置4MB或以上的大对象。每个大型
Region中只会存放一个大对象,大型Region在ZGC的实现中是不会被重分配(重分配是ZGC的一种处理动作,用于复制对象的收集器阶段)的,因为复制一个大对象的代价非常高昂。
ZGC收集器有一个标志性的设计是它采用的染色指针技术,染色指针是一种直接将少量额外的信息存储在指针上的技术
Linux下64位指针的高18位不能用来寻址,但剩余的46位指针所能支持的64TB内存在今天仍然能够充分满足大型服务器的需要。鉴于此,ZGC的染色指针技术继续盯上了这剩下的46位指针宽度,将其高4位提取出来存储四个标志信息。通过这些标志位,虚拟机可以直接从指针中看到其引用对象的三色标记状态、是否进入了重分配集(即被移动过)、是否只能通过finalize()方法才能被访问到。由于这些标志位进一步压缩了原本就只有46位的地址空间,也直接导致ZGC能够管理的内存不可以超过4TB(2的42次幂)
ZGC不通过原始快照或增量更新来实现并发标记,而是通过染色指针
垃圾回收算法
标记-清除算法:
基础算法,后面两个算法基于此算法改进
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。标记过程就是对象是否属于垃圾的判定过程。该算法两个缺点:
- 执行效率不稳定
- 内存碎片化
标记-复制算法:
适用于新生代的算法,将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。如果内存中多数对象都是存活的,这种算法将会产生大量的内存间复制的开销,但对于多数对象都是可回收的情况,算法需要复制的就是占少数的存活对象,而且每次都是针对整个半区进行内存回收,分配内存时也就不用考虑有空间碎片的复杂情况,只要移动堆顶指针,按顺序分配即可。算法缺点很明显:少了一半空间
新生代中的对象有98%熬不过第一轮收集。因此并不需要按照1∶1的比例来划分新生代的内存空间。
标记-整理算法:
针对老年代对象的存亡特征,1974年Edward Lueders提出了另外一种有针对性的 “标记-整理”(Mark-Compact)算法,其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存
分代收集算法:
根据对象存活时间将堆划分为新生代和老年代,新生代使用复制算法,老年代使用标记-整理或标记-清除算法。
三色标记法:
可达性分析算法中,标记过程需要stop the world,保证全局获得一致性快照,这个操作可否与用户线程并发?
先来看三色标记法:把遍历对象图过程中遇到的对象,按照“是否访问过”这个条件标记成以下三种颜色:
-
白色:表示对象尚未被垃圾收集器访问过。显然在可达性分析刚刚开始的阶段,所有的对象都是白色的,若在分析结束的阶段,仍然是白色的对象,即代表不可达,需要被回收
-
黑色:表示对象已经被垃圾收集器访问过,且所有引用了这个对象的对象都已经扫描过。黑色的对象代表已经扫描过,它是安全存活的,不用被回收,如果有其他对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接(不经过灰色对象)指向某个白色对象。
-
灰色:表示对象已经被垃圾收集器访问过,但这个对象上至少存在一个引用还没有被扫描过。是个中间态,当扫描完成后,不会出现这个颜色,整个图非黑即白
可达性分析算法其实就是从GC Roots出发,将图(对象直接的引用关系图)波浪式地由白色转为黑色,其中灰色是黑白之间的过渡色。
这个标记法在用户线程和收集器并发工作下可能存在问题:
是把原本消亡的对象错误标记为存活,这不是好事,但其实是可以容忍的,只不过产生了一点逃过本次收集的浮动垃圾而已,下次收集清理掉就好。
把原本存活的对象错误标记为已消亡,这就是非常致命的后果了,程序肯定会因此发生错误
为什么标记-复制适用于新生代,标记-整理适用于老年代?
新生代需要被清理的对象多,复制只需要复制少量存活对象
老年代存活的对象多,不能使用Eden Survivor那套,不然内存就不够了,当然标记-整理也是一项很负重的操作,但如果不整理,就需要额外使用页表等方式标记哪些空间可用来解决空间碎片化问题,这也会导致额外负担,所以从整个程序的吞吐量考虑,标记-整理是较好的选择
当然老年代也可以先标记-清除,等内存空间碎片化到一定程度时,进行一次标记整理